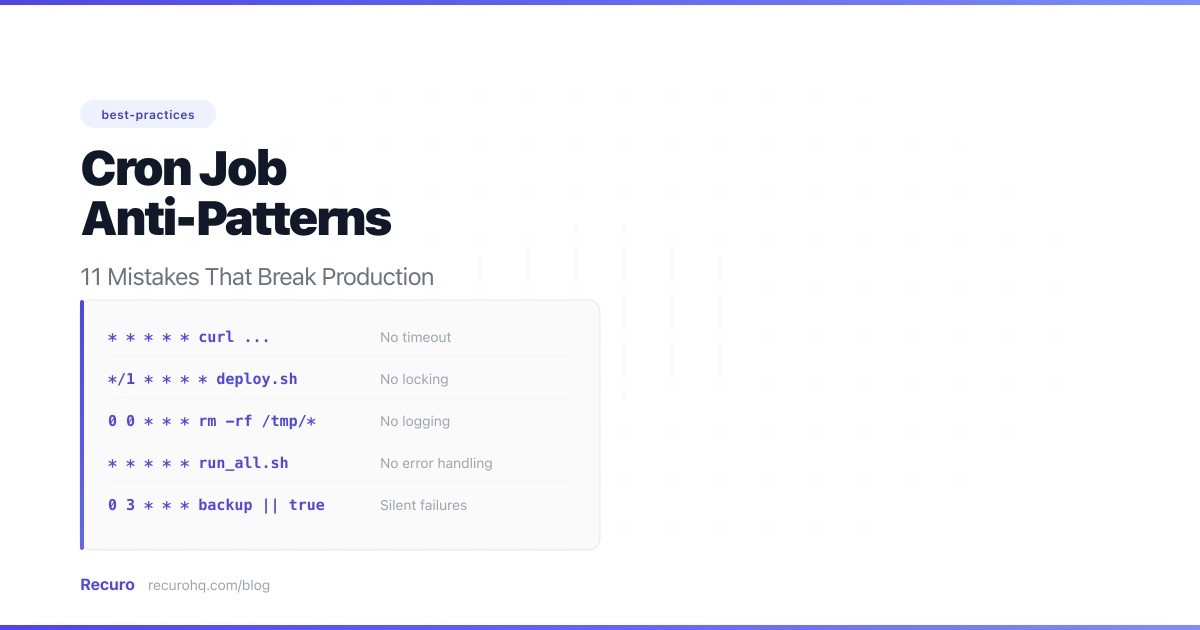
11 Cron Job Mistakes That Will Break Your Production Server
cronbest-practicesopsanti-patterns
Quick Summary — TL;DR
Looking for the how-to guide? This post covers the failure stories — what goes wrong and why. For step-by-step implementation patterns, see Cron Job Best Practices: Logging, Locking, and Monitoring.
Every production outage has a pattern. With cron jobs, the same mistakes show up again and again — across companies, stacks, and experience levels. These are not edge cases. They are the default behavior of cron when you do not actively design against it.
This guide covers each anti-pattern with the concrete failure it causes and the fix that prevents it.
The single most dangerous cron anti-pattern. A non-idempotent job produces different results when it runs twice. Since cron jobs will run twice — due to overlap, retries, DST clock shifts, manual re-execution during incidents, or a scheduler bug — every job must be safe to repeat.
A fintech company ran a nightly revenue aggregation job. One night, the cron daemon restarted mid-execution and re-triggered the job. The INSERT ran twice. Two rows appeared for the same date. The revenue dashboard showed double the actual number. Finance flagged the discrepancy the next morning, but not before an investor report had already gone out with the inflated figure.
# BAD: Inserts a new row every rundef generate_daily_report(): report = calculate_metrics(date.today()) db.execute("INSERT INTO reports (date, revenue) VALUES (?, ?)", report.date, report.revenue)Use upserts, process by state instead of time windows, and include idempotency keys in API calls:
# GOOD: Upsert — safe to run multiple timesdef generate_daily_report(): report = calculate_metrics(date.today()) db.execute(""" INSERT INTO reports (date, revenue) VALUES (?, ?) ON CONFLICT (date) DO UPDATE SET revenue = EXCLUDED.revenue """, report.date, report.revenue)If your job sends emails, charges credit cards, or triggers any irreversible side effect, idempotency is not a nice-to-have. It is the difference between “the job ran twice and nothing happened” and “we billed 10,000 customers twice.” See the cron job best practices guide for more idempotency techniques.
A job scheduled every minute that takes three minutes to complete will stack three concurrent instances. Each one competes for the same database rows, the same files, the same API rate limits.
An e-commerce team scheduled order fulfillment to run every minute. Most days, the job finished in 20 seconds. On Black Friday, the data volume spiked. The job started taking four minutes. Four overlapping instances hit the database, each grabbing the same “pending” orders. Customers received duplicate shipments. The warehouse processed 300 extra packages before anyone noticed.
# Runs every minute, takes 2-5 minutes depending on data volume* * * * * /opt/app/process-orders.shUse flock to ensure only one instance runs at a time:
* * * * * /usr/bin/flock -n /tmp/process-orders.lock /opt/app/process-orders.shThe -n flag makes subsequent invocations exit immediately if the lock is held. For distributed systems where the job runs on multiple servers, use database advisory locks (pg_try_advisory_lock in PostgreSQL, GET_LOCK in MySQL). See the locking section in the best practices guide for detailed patterns.
By default, cron sends stdout and stderr to the user’s local mail spool. On modern servers, local mail is almost never configured. The result: your job fails every night for three weeks, and you find out when a customer reports missing data.
A SaaS team deployed a new server image. The temp-directory cleanup job ran at 3 AM with no output redirection. What they did not notice: a filesystem permission change in the new image caused the script to fail with Permission denied every single night. For three weeks, the errors vanished into the unconfigured local mail spool. Then /tmp filled the disk. The application started returning 500 errors during peak hours. The postmortem traced it back to 21 days of silently failing cleanup.
# No output redirection — failures vanish into /dev/null (effectively)0 3 * * * /opt/app/cleanup.shAlways redirect both stdout and stderr to a log file:
0 3 * * * /opt/app/cleanup.sh >> /var/log/app/cleanup.log 2>&1Better yet, combine logging with monitoring — check exit codes and alert on consecutive failures. A heartbeat ping (dead man’s switch) catches the case where the job stops running entirely.
Credentials pasted directly into crontab entries show up in ps aux output, get captured in logs, and end up in version control when someone commits the crontab file.
A developer added a Stripe API key directly to a crontab entry for a quick billing sync. Months later, the team started version-controlling their server configs — including the crontab file. The live API key landed in a public GitHub repo. An automated scanner found it within hours. Stripe revoked the key proactively, but not before the team scrambled through an emergency credential rotation at 2 AM.
# BAD: API key visible to anyone who can run ps0 * * * * curl -H "Authorization: Bearer sk_live_abc123" https://api.stripe.com/v1/chargesEven without version control exposure, every process on the system can see this command and its arguments via ps aux.
Load secrets from an environment file with restricted permissions:
0 * * * * /opt/app/sync-charges.sh#!/bin/bashset -euo pipefailsource /etc/app/cron.env # owned by root, chmod 0600
curl -sf -H "Authorization: Bearer $STRIPE_API_KEY" \ https://api.stripe.com/v1/chargesThe cron.env file stays out of version control (add it to .gitignore) and is readable only by root.
A job with no timeout can run forever. A hung database connection, a slow API response, or an infinite loop will hold the lock (if you have one) indefinitely, blocking all future runs.
An inventory sync ran every 5 minutes and normally completed in 10 seconds. One Thursday, the upstream API started responding in 300 seconds instead of 2 — a degradation, not a full outage, so no alerts fired on their end. The sync script blocked on curl with no timeout. Because the team had correctly added flock, the lock was held by the hung process and every subsequent run exited immediately. Six hours of inventory data went unsynced. The online store showed items as “in stock” that had already sold out in the warehouse.
# This job normally takes 10 seconds. One day the API hangs.*/5 * * * * /opt/app/sync-inventory.shSet explicit timeouts at every layer:
# timeout kills the process after 120 seconds*/5 * * * * /usr/bin/timeout 120 /usr/bin/flock -n /tmp/inventory.lock /opt/app/sync-inventory.shInside your scripts, set HTTP timeouts too:
curl --max-time 30 --connect-timeout 5 -sf https://api.example.com/inventoryThe outer timeout is your safety net. The inner --max-time handles the common case. Both are necessary.
Cron runs with a minimal environment: a stripped-down PATH (usually just /usr/bin:/bin), /bin/sh as the default shell, no loaded profile, and no working directory. Commands that work perfectly in your terminal fail silently in cron.
A developer tested a Python sync script from their terminal: python3 sync.py. It worked perfectly. They added it to crontab the same way. It never ran successfully — not once. The python3 binary was in /usr/local/bin/, outside cron’s default PATH. The script referenced config.json with a relative path, but cron’s working directory is /, not the project folder. Both failures produced errors that went to the unconfigured mail spool (anti-pattern #3). The developer only discovered the problem a week later when a manager asked why the integration data was stale.
# BAD: relies on PATH having python3, assumes working directory0 * * * * python3 sync.pyUse absolute paths for everything. Set PATH and SHELL at the top of your crontab:
PATH=/usr/local/bin:/usr/bin:/binSHELL=/bin/bash
0 * * * * cd /opt/app && /usr/local/bin/python3 /opt/app/sync.py >> /var/log/app/sync.log 2>&1The cron job troubleshooting guide covers this in detail — it is the most common reason a cron job works manually but fails when scheduled.
The obvious time to run daily jobs is midnight. Every developer thinks the same thing. The result: a thundering herd at 00:00 where every backup, cleanup, report, and sync job fires simultaneously.
A growing team added cron jobs organically over two years. Each developer independently chose 0 0 * * * — midnight — because it seemed like a safe, quiet time. By the time they had eight jobs all firing at 00:00, the nightly window was anything but quiet. The database backup locked tables while the report generator ran heavy aggregation queries against those same tables. The session cleanup saturated disk I/O. The connection pool maxed out. Jobs that normally took 30 seconds ballooned to 15 minutes. The backup timed out and failed, which meant the morning restore-test job had nothing to restore from — a cascading failure nobody saw coming.
# Four jobs all competing for resources at midnight0 0 * * * /opt/app/backup-database.sh0 0 * * * /opt/app/generate-reports.sh0 0 * * * /opt/app/cleanup-sessions.sh0 0 * * * /opt/app/sync-inventory.shStagger your jobs. Spread them across the hour — or across the night:
0 0 * * * /opt/app/backup-database.sh # Midnight — runs first, alone15 0 * * * /opt/app/generate-reports.sh # 00:15 — after backup completes30 0 * * * /opt/app/cleanup-sessions.sh # 00:3045 0 * * * /opt/app/sync-inventory.sh # 00:45For jobs that do not need to run at a specific time, use random offsets or pick off-peak hours. The thundering herd problem applies to cron just as much as it applies to retry logic.
Most teams monitor for job failures — an exit code other than zero. Almost nobody monitors for jobs that stop running entirely. If the cron daemon crashes, the server reboots without starting cron, or someone accidentally deletes a crontab entry, there is nothing to fail — so nothing to alert on.
A team migrated their application to a new server. The runbook covered the app deploy, the database connection, the load balancer — everything except the crontab. The nightly billing reconciliation stopped running. There were no errors, no alerts, no failed jobs — because the job simply was not there anymore. Twelve days later, accounting flagged a $40,000 discrepancy between payment processor records and the internal ledger. The reconciliation had not run since the migration, and every day the gap grew wider.
Use heartbeat monitoring (dead man’s switch). The job pings a monitoring endpoint on success. If no ping arrives within the expected window, you get an alert:
0 2 * * * /opt/app/billing-reconcile.sh && curl -sf https://monitor.example.com/ping/billing-abc > /dev/nullThe && ensures the ping only fires on success. This catches both “it ran and failed” and “it stopped running entirely” — the second being far more dangerous because it is invisible without this pattern.
With Recuro, missed-execution detection is built in. Every scheduled job has an expected execution window, and alerts fire automatically when a run is missed.
A job that processes “all records from the last hour” breaks when the job runs late, runs twice, or skips a run. Time-window processing creates gaps and overlaps that are hard to detect and harder to fix.
An order fulfillment job ran hourly and processed “all orders from the last 60 minutes.” It worked fine for months. Then a database migration ran long and delayed the cron job by 8 minutes. Orders placed between 60 and 68 minutes before the delayed run fell into a gap — outside the 60-minute window. Fourteen orders never got fulfilled. Customer support started getting “where’s my order?” tickets the next day. The tricky part: the job itself reported success. It processed everything in its window perfectly. The gap was invisible without manually cross-referencing order timestamps against job execution times.
# BAD: Time-window processingdef process_new_orders(): one_hour_ago = datetime.now() - timedelta(hours=1) orders = db.query("SELECT * FROM orders WHERE created_at > ?", one_hour_ago) for order in orders: fulfill(order)Process by state, not time:
# GOOD: State-based processingdef process_new_orders(): orders = db.query("SELECT * FROM orders WHERE status = 'pending' FOR UPDATE SKIP LOCKED") for order in orders: fulfill(order) db.execute("UPDATE orders SET status = 'fulfilled' WHERE id = ?", order.id)FOR UPDATE SKIP LOCKED prevents concurrent instances from grabbing the same rows. The state transition (pending → fulfilled) makes the job naturally idempotent. Late runs catch up. Duplicate runs are harmless.
The most fragile architecture: your cron jobs run on the same server as your application, often via crontab entries on that machine. When the server goes down — for a deploy, a crash, or planned maintenance — your scheduled jobs go down with it.
A startup ran php artisan schedule:run on their single web server. It worked for a year. Then they deployed a new version during off-hours. The server restarted. For two minutes, no cron jobs ran. The payment retry that was due at exactly that moment was missed. A customer’s subscription lapsed. Support got a complaint the next morning.
They scaled to two servers and added crontab to both — now every job ran twice. They fixed that by keeping crontab on only one server. Six months later, that server had a hardware failure at 4 AM. The other server kept serving web traffic fine, but every scheduled job stopped. Nobody noticed until morning because there was nothing to fail — the cron daemon was simply gone.
# On your web server's crontab*/5 * * * * cd /var/www/app && php artisan schedule:runThe core problem is coupling scheduling to a single machine. There are several ways to decouple it:
Dedicated scheduling server. Run cron on a small, separate instance whose only job is scheduling. It does not serve traffic, so deploys to your application servers do not affect it. This is the simplest fix and works well for small-to-medium workloads.
Distributed locking. Keep cron on every application server but use a distributed lock (Redis SET NX EX, PostgreSQL pg_try_advisory_lock, MySQL GET_LOCK) so only one server executes each job per tick. Laravel’s onOneServer() method does exactly this. The scheduler runs everywhere, but the lock ensures single execution.
Leader election. In Kubernetes or container orchestration environments, use a leader election mechanism (e.g., Kubernetes Lease objects, Consul sessions, or etcd elections) so only the elected leader runs the cron daemon. If the leader dies, a new one is elected automatically.
Systemd timers with high availability. On systemd-based servers, use systemd timers instead of cron. Combined with a Pacemaker/Corosync cluster or systemd’s own watchdog and restart policies, you get automatic recovery if the scheduling process dies.
Managed scheduling services. External schedulers like Recuro, AWS EventBridge Scheduler, or GCP Cloud Scheduler call your HTTP endpoints on schedule from outside your infrastructure. Your servers become stateless — they handle the request and return a response without needing to know about schedules. This eliminates the single-point-of-failure problem entirely but adds a dependency on an external service.
The right choice depends on your stack. If you already use Redis, distributed locking is a one-line fix. If you are on Kubernetes, leader election is native. If you want zero infrastructure to manage, an external scheduler removes the problem from your plate.
The % character has special meaning in crontab: cron treats the first % as a newline and pipes everything after it as stdin to the command. This is one of the most common and least-known cron gotchas. It is not a shell issue — it is crontab-specific parsing that happens before the shell ever sees the command.
A developer added a job to archive log files with a date stamp:
# BAD: % has special meaning in crontab0 1 * * * tar -czf /backups/logs-$(date +%Y-%m-%d).tar.gz /var/log/app/This command works perfectly when pasted into a terminal. In crontab, it silently breaks. Cron interprets %Y as a newline followed by Y, turning the command into garbage. The tar command receives a truncated argument and fails — or worse, creates a file with a mangled name like logs-.tar.gz every night while the actual date-stamped archives never appear. Because the error behavior depends on exactly where the % falls, it can take days to figure out what is wrong.
The same problem bites any crontab entry with date formatting, printf format strings, URL-encoded parameters (%20, %3A), or SQL queries with LIKE '%pattern%'.
Escape every % as \% in crontab entries:
# GOOD: Escaped percent signs0 1 * * * tar -czf /backups/logs-$(date +\%Y-\%m-\%d).tar.gz /var/log/app/Or move the command into a script file, where % has no special meaning:
0 1 * * * /opt/app/archive-logs.sh#!/bin/bash# Inside a script, % works normally — no escaping neededtar -czf "/backups/logs-$(date +%Y-%m-%d).tar.gz" /var/log/app/The script approach is generally better: it avoids the % escaping issue, keeps the crontab readable, and makes the command testable outside of cron.
These anti-patterns rarely appear alone. A job with no locking runs twice, hits a non-idempotent handler, fails silently because there is no logging, and nobody notices because there is no monitoring. One mistake might be survivable. Three together cause an outage.
The fix is not heroic debugging. It is building the right defaults:
flock for single-server, database advisory locks for distributed% in crontab — or move commands into script filesFor implementation details on each of these, see the cron job best practices guide.
The most common mistake is not making jobs idempotent — meaning the job produces different results when it runs more than once. Since cron jobs will inevitably run twice due to overlapping executions, retries, DST clock shifts, or manual re-runs during incidents, a non-idempotent job can cause duplicate database records, double billing, or corrupted data. Use database upserts, process records by state instead of time windows, and include idempotency keys in API calls.
Use flock, which is part of util-linux and available on virtually every Linux system. Wrap your crontab command: /usr/bin/flock -n /tmp/myjob.lock /path/to/script.sh. The -n flag makes flock exit immediately if another instance holds the lock. For jobs that run on multiple servers, use database advisory locks (pg_try_advisory_lock in PostgreSQL, GET_LOCK in MySQL) instead of file-based locks.
Cron sends output to the user's local mail spool by default, which is almost never configured on modern servers. If you do not redirect stdout and stderr to a log file, error output simply vanishes. Fix this by appending >> /var/log/app/job.log 2>&1 to every crontab entry. Then add heartbeat monitoring so you are alerted when jobs stop running entirely — not just when they fail.
No. Scheduling all daily jobs at midnight creates a thundering herd where every backup, report, cleanup, and sync job competes for CPU, memory, database connections, and I/O simultaneously. Stagger your jobs across the hour or night — run backups at midnight, reports at 00:15, cleanup at 00:30, and so on. For jobs that do not need a specific time, pick off-peak hours.
Time-window processing (e.g., 'process all records from the last hour') breaks when the job runs late, runs twice, or skips a run. Late runs create gaps where records are missed. Duplicate runs process the same records twice. Instead, process by state: query records WHERE status = 'pending', process them, then update the status to 'processed'. This makes the job naturally idempotent and self-healing.
Never put credentials directly in crontab entries — they appear in process listings (ps aux) and may end up in version control. Instead, store secrets in an environment file (e.g., /etc/app/cron.env) with restricted permissions (chmod 0600, owned by root). Source this file at the top of your cron scripts. Keep the env file out of version control by adding it to .gitignore.
Running cron on your application server creates a single point of failure. When the server restarts for a deploy, crash, or maintenance, all scheduled jobs stop. Scaling to multiple servers creates a different problem: jobs run once per server, causing duplicates. Fix this with distributed locking (Redis SET NX, database advisory locks), leader election (Kubernetes Lease objects, Consul), a dedicated scheduling server, or an external HTTP-based scheduler that calls your endpoints independently of your infrastructure.
In crontab, the % character has special meaning: cron treats the first % as a newline and feeds everything after it as stdin to the command. This means commands like date +%Y-%m-%d get silently mangled before the shell sees them. Escape every % as \% in crontab entries, or move the command into a separate script file where % has no special meaning. This is one of the most common reasons a command works in a terminal but fails in cron.
Recuro handles cron scheduling, retries, alerts, and execution logs — so you can focus on building your product.
No credit card required